
My research focuses on computer vision and deep learning for embodied intelligence. I often wonder how it is that spatial understanding, object permanence, and intuitive physics come so naturally to both humans and animals, and try to enable the same within AI systems. Specifically, I focus on spatial reasoning in dynamic scenes, especially in the context of 3D/4D/video representations, as well as generative models. I am also excited by efforts to learn from (both natural and synthetic) visual data without requiring all too much manual annotation, or even none whatsoever. Check out some of my projects below for an overview of what I have done so far! (Note: this page is usually outdated, please see Google Scholar instead for a more comprehensive list.)
Generative Camera Dolly: Extreme Monocular Dynamic View Synthesis
(Basile Van Hoorick, Rundi Wu, Ege Ozguroglu, Kyle Sargent, Ruoshi Liu, Pavel Tokmakov, Achal Dave, Changxi Zheng, Carl Vondrick; Published in ECCV 2024 with oral presentation)
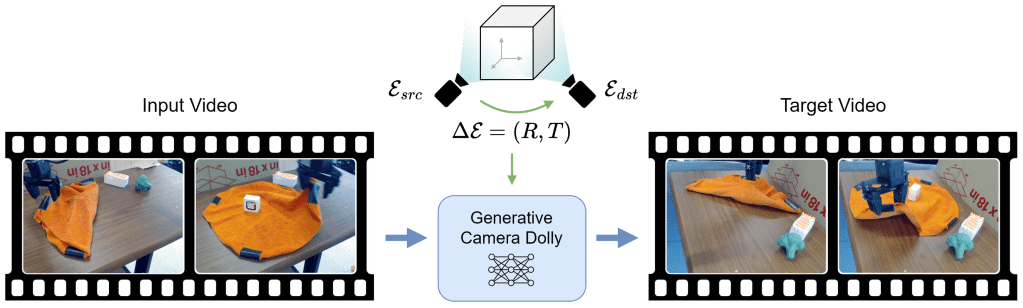
Accurate reconstruction of complex dynamic scenes from just a single viewpoint continues to be a challenging task in computer vision. Current dynamic novel view synthesis methods typically require videos from many different camera viewpoints, necessitating careful recording setups, and significantly restricting their utility in the wild as well as in terms of embodied AI applications. In this paper, we propose a controllable monocular dynamic view synthesis pipeline that leverages large-scale diffusion priors to, given a video of any scene, generate a synchronous video from any other chosen perspective, conditioned on a set of relative camera pose parameters. Our model does not require depth as input, and does not explicitly model 3D scene geometry, instead performing end-to-end video-to-video translation in order to achieve its goal efficiently. Despite being trained on synthetic multi-view video data only, zero-shot real-world generalization experiments show promising results in multiple domains, including robotics, object permanence, and driving environments. We believe our framework can potentially unlock powerful applications in rich dynamic scene understanding, perception for robotics, and interactive 3D video viewing experiences for virtual reality.
Link to paper / Link to project website / Link to GitHub repository
Tracking through Containers and Occluders in the Wild
(Basile Van Hoorick, Pavel Tokmakov, Simon Stent, Jie Li, Carl Vondrick; Published in CVPR 2023)

Tracking objects with persistence in cluttered and dynamic environments remains a difficult challenge for computer vision systems. In this paper, we introduce a new benchmark for visual tracking through heavy occlusion and containment. We set up a task where the goal is to, given a video sequence, segment both the projected extent of the target object, as well as the surrounding container or occluder whenever one exists. To study this task, we create a mixture of synthetic and annotated real datasets to support both supervised learning and structured evaluation of model performance under various forms of task variation, such as moving or nested containment. We evaluate two recent transformer-based video models and find that while they can be surprisingly capable of tracking targets under certain settings of task variation, there remains a significant performance gap before we can claim a tracking model to have acquired a true notion of object permanence.
Link to paper / Link to project website / Link to GitHub repository
Zero-1-to-3: Zero-shot One Image to 3D Object
(Ruoshi Liu, Rundi Wu, Basile Van Hoorick, Pavel Tokmakov, Sergey Zakharov, Carl Vondrick; Published in ICCV 2023)
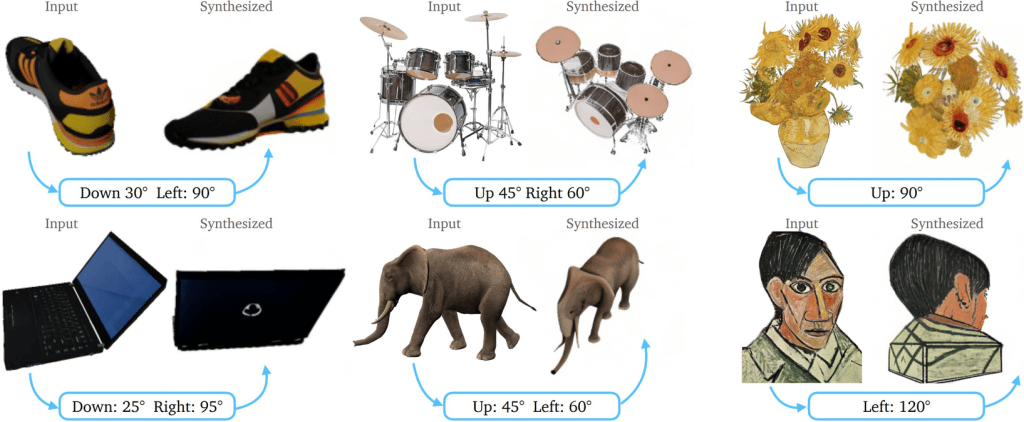
We introduce Zero-1-to-3, a framework for changing the camera viewpoint of an object given just a single RGB image. To perform novel view synthesis in this under-constrained setting, we capitalize on the geometric priors that large-scale diffusion models learn about natural images. Our conditional diffusion model uses a synthetic dataset to learn controls of the relative camera viewpoint, which allow new images to be generated of the same object under a specified camera transformation. Even though it is trained on a synthetic dataset, our model retains a strong zero-shot generalization ability to out-of-distribution datasets as well as in-the-wild images, including impressionist paintings. Our viewpoint-conditioned diffusion approach can further be used for the task of 3D reconstruction from a single image. Qualitative and quantitative experiments show that our method significantly outperforms state-of-the-art single-view 3D reconstruction and novel view synthesis models by leveraging Internet-scale pre-training.
Link to paper / Link to project website / Link to GitHub repository / Link to live demo
Revealing Occlusions with 4D Neural Fields
(Basile Van Hoorick, Purva Tendulkar, Didac Suris, Dennis Park, Simon Stent, Carl Vondrick; Published in CVPR 2022 with oral presentation)

visual recognition tasks, such as predicting its location, reconstructing its appearance, and classifying its semantic category.
For computer vision systems to operate in dynamic situations, they need to be able to represent and reason about object permanence. We introduce a framework for learning to estimate 4D visual representations from monocular RGB-D, which is able to persist objects, even once they become obstructed by occlusions. Unlike traditional video representations, we encode point clouds into a continuous representation, which permits the model to attend across the spatiotemporal context to resolve occlusions. On two large video datasets that we release along with this paper, our experiments show that the representation is able to successfully reveal occlusions for several tasks, without any architectural changes. Visualizations show that the attention mechanism automatically learns to follow occluded objects. Since our approach can be trained end-to-end and is easily adaptable, we believe it will be useful for handling occlusions in many video understanding tasks.
Link to paper / Link to project website / Link to GitHub repository
Dissecting Image Crops
(Basile Van Hoorick, Carl Vondrick; Published in ICCV 2021)
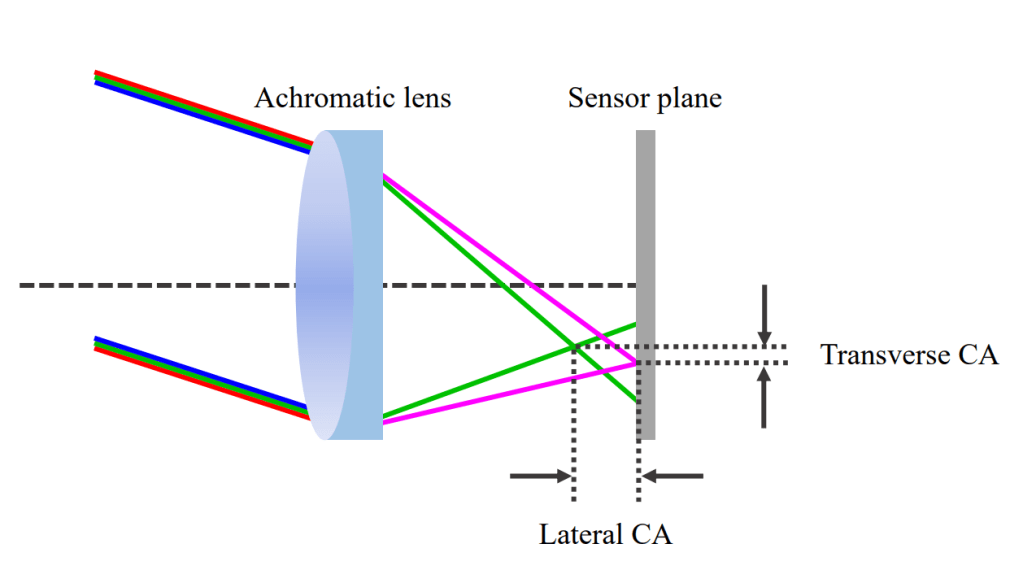
The elementary operation of cropping underpins nearly every computer vision system, ranging from data augmentation and translation invariance to computational photography and representation learning. This paper investigates the subtle traces introduced by this operation. For example, despite refinements to camera optics, lenses will leave behind certain clues, notably chromatic aberration and vignetting. Photographers also leave behind other clues relating to image aesthetics and scene composition. We study how to detect these traces, and investigate the impact that cropping has on the image distribution. While our aim is to dissect the fundamental impact of spatial crops, there are also a number of practical implications to our work, such as detecting image manipulations and equipping neural network researchers with a better understanding of shortcut learning.
Link to paper / Link to GitHub repository
Image Outpainting using GANs
(Basile Van Hoorick; In a course by Prof. Peter Belhumeur)
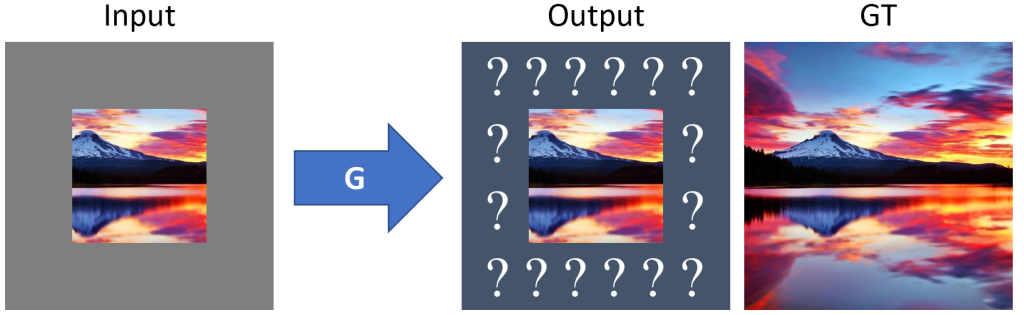
Inpainting, which attempts to recover holes within photos, is an active line of research and typically uses Generative Adversarial Networks. However, the opposite problem of predicting what pixels reside outside the borders of an image (hence the term outpainting) is something I would also deem worthy of investigation. Many architectural aspects and ideas can moreover be naturally adopted from inpainting. Check out the submission on arXiv below to see which hallucinations our model has come up with!
Link to paper / Link to GitHub repository
FPGA-based Simultaneous Localization and Mapping using High-Level Synthesis
(Basile Van Hoorick; Supervised by Prof. Erik D’Hollander and Prof. Bart Goossens)

This master’s thesis at Ghent University was an exploration of a robotic navigation algorithm called Simultaneous Localization and Mapping (SLAM), which helps autonomous agents track their location within an environment while at the same time creating a dense model of that very environment. In an effort to implement a 3D variant of this application on embedded systems (more specifically, Field-Programmable Gate Arrays or FPGAs), I devised guidelines to facilitate the translation of platform-agnostic C/C++ code to FPGA-optimized designs using the High-Level Synthesis (HLS) design technique. Furthermore, I implemented and compared several mappings of typical software blocks to efficient dataflow architectures on programmable hardware.
