While working on my current Master’s thesis involving FPGA development, I found that it was hard to find readable examples of intrinsically two-dimensional filters that cannot be simply decomposed into a horizontal and a vertical convolution, in a way that e.g. a Gaussian filter or a Sobel filter can. Non-separable convolutions or filters require you to calculate every output pixel as a function of its surrounding input pixels, i.e. a window that extends in both dimensions at once. After reviewing multiple sources and trying out various methods myself, I believe to have found a fast and resource-efficient way to do it! Note that the existing HLS OpenCV libraries already include functionality for various possible applications, although the approach presented here is generally applicable and perfectly supports many more kinds of 2D filtering operations. In order to keep the length of this article at bay, I will assume that you are at least somewhat familiar with Field-Programmable Gate Arrays (FPGAs), High-Level Synthesis (HLS) and the concept of pipelining.
Background and task
HLS is a wonderful technology which vastly reduces the design time of complex hardware logic. However, any user will quickly see that, despite being admitted to use a well-known software programming language (C/C++) for the task of designing hardware logic, many characteristic difficulties of hardware development still remain noticeable and perhaps even unavoidable. Performing filter operations efficiently is one such task that is much less trivial to implement on an FPGA than on a regular processor.
While filters and convolutions are not exactly the same thing, the knowledge in this article applies to both of them. Even non-linear filters such as the bilateral filter can use this technique since there are no constraints on how the window is used during processing. Anyway, let’s consider a random image (shown below) as an example and perform a non-separable edge detection operation:

It is important to know that most FPGAs cannot fit a full image on the order of 1 MB onto their block RAM or other forms of local storage. Therefore, the data will have to be read from and written to a memory location outside of the FPGA in real time during the execution.
Version 1: a naive implementation
A straightforward implementation that would work just fine on a CPU is shown below. Side note: I added two HLS directives (PIPELINE and ARRAY_PARTITION), please refer to this guide if you’re uncertain about what these mean.
#define WIN_SIZE 3 // must be odd #define HALF_SIZE (((WIN_SIZE) - 1) / 2) inline bool bounds_ok(int y, int x) { return (0 <= y && y < HEIGHT && 0 <= x && x < WIDTH); } // Defines the actual calculation for one output value. inline int single_operation(int window[3][3], int y, int x) { int result = 0; win_i : for (int i = -HALF_SIZE; i <= HALF_SIZE; i++) win_j : for (int j = -HALF_SIZE; j <= HALF_SIZE; j++) if (bounds_ok(y + i, x + j)) result += window[i + HALF_SIZE][j + HALF_SIZE] * (i + j); return result; } // A simple implementation of a 2D filter. void my_filter_v1(int data_out[HEIGHT][WIDTH], const int data_in[HEIGHT][WIDTH]) { int window[WIN_SIZE][WIN_SIZE]; #pragma HLS ARRAY_PARTITION variable=window complete for_y : for (int y = 0; y < HEIGHT; y++) { for_x : for (int x = 0; x < WIDTH; x++) { #pragma HLS PIPELINE // Load window load_i : for (int i = -HALF_SIZE; i <= HALF_SIZE; i++) load_j : for (int j = -HALF_SIZE; j <= HALF_SIZE; j++) if (bounds_ok(y + i, x + j)) window[i + HALF_SIZE][j + HALF_SIZE] = data_in[y + i][x + j]; // Calculate output value int val_out = single_operation(window, y, x); data_out[y][x] = val_out; } } }
So what exactly is wrong with this code? The problem is that communication with the outside world is expensive. The amount of simultaneous I/O accesses per clock cycle is strictly limited, creating a bottleneck which becomes even worse for large window sizes. For a 3×3 window, 9 input pixels have to be read for every single write to an output pixel. To illustrate this bottleneck, let’s synthesize our project on the Zedboard (Zynq 7020 SoC) and analyze the results:

Clearly, the excessive amount of read operations is slowing down the global throughput. The pipelined initiation interval is forced to be at least 5 clock cycles, because it is constrained by the I/O bottleneck. As a result, only one output pixel gets calculated every 5 cycles. However, this is a best case scenario because HLS does not take into account the real-world communication overhead at all. If we implement this on a System-on-Chip with an AXI master interface for example, the actual initiation interval will inevitably increase even further! So, how can we circumvent these issues and maximize the throughput in regime?
Version 2: efficient streaming using line buffers
The solution is to ensure that data_out and data_in should be accessed as few times as possible. The ideal case is of course that every position gets accessed just once during the whole execution. Luckily, this can be done by using two cooperating data structures: a line buffer and a window.
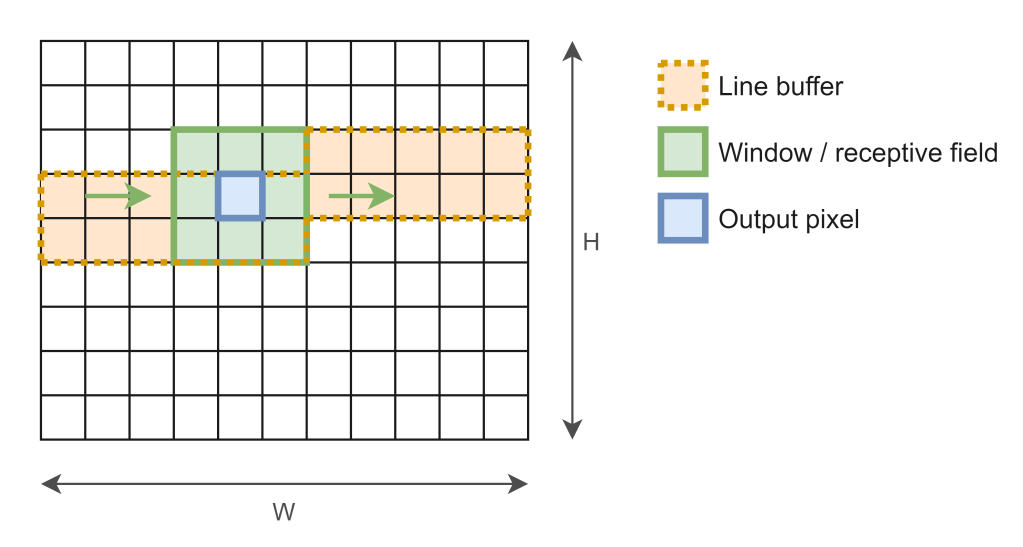
The figure above shows how the input pixels are stored at any point in time for a 3*3 window. The line buffer has dimensions 2*width and serves as sort of a cache that fits just enough elements to fill the rightmost column of the window when it shifts at every new iteration. As such, only one new input pixel has to be read from the I/O port into the window on every clock cycle. Before we jump into the details of the code, here is the report:


Indeed, every iteration consists of just one read (C6) and one write (C11) to the external data stream. Thanks to this technique, the throughput can finally reach its optimal value of one output pixel per clock cycle!
Final code
#include "hls_stream.h" #define WIN_SIZE 3 // must be odd #define HALF_SIZE (((WIN_SIZE) - 1) / 2) inline bool bounds_ok(int y, int x) { return (0 <= y && y < HEIGHT && 0 <= x && x < WIDTH); } // Defines the actual calculation for one output value. inline int single_operation(int window[WIN_SIZE][WIN_SIZE], int y, int x) { int result = 0; win_i : for (int i = -HALF_SIZE; i <= HALF_SIZE; i++) win_j : for (int j = -HALF_SIZE; j <= HALF_SIZE; j++) if (bounds_ok(y + i, x + j)) result += window[i + HALF_SIZE][j + HALF_SIZE] * (i + j); return result; } // A buffered implementation of a 2D filter. void my_filter_buffer(hls::stream<int>& out_stream, hls::stream<int>& in_stream) { int line_buf[WIN_SIZE - 1][WIDTH]; int window[WIN_SIZE][WIN_SIZE]; int right[WIN_SIZE]; #pragma HLS ARRAY_PARTITION variable=line_buf complete dim=1 #pragma HLS ARRAY_PARTITION variable=window complete dim=0 #pragma HLS ARRAY_PARTITION variable=right complete // Load initial values into line buffer int read_count = WIDTH * HALF_SIZE + HALF_SIZE + 1; buf_x1 : for (int x = WIDTH - HALF_SIZE - 1; x < WIDTH; x++) #pragma HLS PIPELINE line_buf[HALF_SIZE - 1][x] = in_stream.read(); buf_y : for (int y = HALF_SIZE; y < WIN_SIZE - 1; y++) buf_x2 : for (int x = 0; x < WIDTH; x++) #pragma HLS PIPELINE line_buf[y][x] = in_stream.read(); // Copy initial values into window win_y : for (int y = HALF_SIZE; y < WIN_SIZE; y++) win_x : for (int x = HALF_SIZE; x < WIN_SIZE; x++) #pragma HLS PIPELINE window[y][x] = line_buf[y - 1][x + WIDTH - WIN_SIZE]; // Start convolution for_y : for (int y = 0; y < HEIGHT; y++) { for_x : for (int x = 0; x < WIDTH; x++) { #pragma HLS PIPELINE // Calculate output value int val_out = single_operation(window, y, x); // Write output value out_stream.write(val_out); // Shift line buffer column up right[0] = line_buf[0][x]; for (int y = 1; y < WIN_SIZE - 1; y++) right[y] = line_buf[y - 1][x] = line_buf[y][x]; // Read input value int val_in = 0; if (read_count < HEIGHT * WIDTH) { val_in = in_stream.read(); read_count++; } right[WIN_SIZE - 1] = line_buf[WIN_SIZE - 2][x] = val_in; // Shift window left for (int y = 0; y < WIN_SIZE; y++) for (int x = 0; x < WIN_SIZE - 1; x++) window[y][x] = window[y][x + 1]; // Update rightmost window values for (int y = 0; y < WIN_SIZE; y++) window[y][WIN_SIZE - 1] = right[y]; } } }
A few observations:
- HLS streams are used to enforce the desired single-read and single-write behaviour.
- Before starting the loop, the buffer is initially filled with a few rows of input pixels. This is to ensure that enough data is available to produce one output value right from the first iteration. There exist various alternative approaches, though.
- The method
single_operationcan be modified to your liking and must not necessarily contain a linear operation. It also knows the image position you are currently processing so that boundary effects can be handled well. - The line buffer is partitioned vertically (i.e. across rows only), so that vertical shifting can happen without dependency constraint problems. Every iteration, one column is shifted up so that the ‘net result’ after one row is that the whole line buffer is shifted up as well.
- The window on the other hand is partitioned in both dimensions, e.g. a 7×7 window will produce 49 separate registers so that they can be accessed (and shifted) fully in parallel.
- If your window becomes too large and/or your filter operation too complex, it is likely that resources may skyrocket because we employ pipelining in order to keep the throughput high. Luckily though, the memory usage should not be a concern anymore.
I hope this helped. Feel free to leave a comment with any question or suggestion!

Hello, I am working on a project to apply different filters on an input image (Bilateral filter etc..) through HW.
Do you think you can enlighten me on how you can use the last IP core with an image (openCV) through the test bench? I don’t really understand the image to an AXI stream conversion for this example.
Regards
Gilles
LikeLike
Hi Gilles,
Great question. The key is to use a Matrix datatype from OpenCV. HLS has an OpenCV library in the form of “hls_opencv.h”, which you can find more about here:
https://www.xilinx.com/support/documentation/sw_manuals/xilinx2019_1/ug1233-xilinx-opencv-user-guide.pdf
I also created a small code example to illustrate how it can be used:
This file contains hidden or bidirectional Unicode text that may be interpreted or compiled differently than what appears below. To review, open the file in an editor that reveals hidden Unicode characters.
Learn more about bidirectional Unicode characters
bilateral_filter_test.cpp
hosted with ❤ by GitHub
By the way, if this is relevant to you, I have also covered the optimization of a bilateral filter in my thesis – if you are interested, feel free to check out:
https://lib.ugent.be/fulltxt/RUG01/002/786/298/RUG01-002786298_2019_0001_AC.pdf
Hope this helps!
LikeLike
Thank you very much for the example ! And yes there is a lot of information in your thesis that helps me understand more of the HLS workflow and the design of these filters.
Cheers !
LikeLike
Would you also by any chance have a good reference(or example) to understand DMA/BRAM/DRAM implementation into a PetaLinux OS? So you would be able to acces while running the OS platform.
Big thanks for the help given already !
Regards
Gilles L.
LikeLike
Writing software around your hardware platform is a very configuration- and device-specific thing that varies from case to case. A lot of documentation in this world is unfortunately not so easy to find nor of the best quality. Nevertheless, try looking up guides/articles that are tailored toward your OS or development board, there should be at least some basic examples that demonstrate communication between the CPU and FPGA. The block design in Vivado is a challenging aspect in my opinion, but I found that YouTube tutorials helped me understand AXI DMA. Good luck!
Best, Basile
LikeLike
Hello again,
Last time you helped me to understand the conversion in the testbench and everything validates perfectly for my design. Deploying this filter core in hardware on a bare metal application is where I don’t understand the image transfer and storage in the hardware (Minized DDR). I have been searching forums/references/papers, but most of the information I find is Video based with a camera input and output rather than an image. So you are kind of ‘my last hope’.
I’ve tried with a DMA linked to the IP-core (filter) in my block design and would think when I setup a transfer with image data in array format(640×480 unsigned char) to the filter it would be in the AXI Stream format protocol. Yet doing this makes the transfer get stuck where I think it is not in the correct format to the filter ? The filter does expect a stream as below :
typedef hls::stream<ap_axiu > AXI_STREAM;
void filter(AXI_STREAM& video_in, AXI_STREAM& video_out)
{
//Create axi streaming interfaces for core.
#pragma HLS INTERFACE axis port=video_in
#pragma HLS INTERFACE axis port=video_out
hls::Mat2AXIvideo(img_4, video_out);
……
……
}
I have tried with a AXIS subset converter to ensure the data.last = 1 when the transfer is done, but I might be searching in the complete wrong direction. If you have any insights on this I would greatly appreciate it. I am breaking my head on how to process a simple image in the hardware with memory management..
Again thank for the fast reply & help before
Gilles
LikeLike
Hi,
The block design itself (IP core + AXI DMA) sounds good. I personally used a datatype struct with the last signal only, but yours should work as well. I don’t think an AXIS subset converter is needed here, but don’t quote me on this. Are you using Xilinx SDK for the software platform and calling XAxiDma_SimpleTransfer()? If so, did you try disabling cache?
LikeLike
Hello
Did you use this struct as the input streams to the block or as side channels inside the core function?
You are right about the converter, it it unnecessary. I am using Vitis with the XAxiDma_SimpleTransfer(). Calling Xil_DCacheDisable(); & Xil_ICacheDisable(); doesn’t work either.
To understand the transfers I created a simple gain core function with an array of 1000 ints as inputs and debugged it with an ILA. From what I understand is as soon as I change the input array size from 1000 to 1 higher or 1 lower the DMA wont transfer anything at all. Maybe this means I am incorrectly sending/reading the image in Vitis ? I have used a matlab script to generate an input array of chars.
Would love to hear your opinion on this.
thanks for all the help
Gilles
LikeLike
Hi Gilles,
If I understand your question correctly, I meant to say that I used hls_stream<data_t> for input and output where data_t is a struct consisting of for example a 32-bit int/float and 1-bit ‘last’ flag. Vitis is something I’ve never used or heard of, so the advice I can give is unfortunately going to be relatively superficial. I would try to ensure that the array size is always a multiple of 4, and also that the length register is sufficiently large (I remember the standard bitwidth being rather small, this can be adjusted somewhere in the Vivado block design, but I don’t recall the exact details). It’s good that you do have at least one working program though – one thing you could try as a general approach is to find an example (online / tutorial / whereever) that is most closely related to your project, and incrementally change things by small steps at a time toward your specific goal, thus pinpointing any issues along the way.
Hope this helps in some way!
Basile
LikeLike
Hello
Transferring an image array should be the same as the integer array right?
Finding examples with a video input is sufficient, with an image not so much so it is hard to find a good start. Vitis is part of the Xilinx 2019.2 design suite. In older version this was the SDK environment and so they are almost the same with extra additions. Again thanks for the help and your time.
Gilles
LikeLike
Well, in case of RGBA/ARGB/etc. with 4 bytes, then yes you have an array of 32-bit integers covering one pixel per value (make sure to double check the format though, because many data types exist for images, but of course you can control that yourself in the surrounding software).
LikeLike
Hello, great Scholas!
By any chance, can someone kindly help out with this my final project task? This is my first time learning this course and it is a bit difficult for me to understand. Below are the details to perform the task in VIVADO.
Lab requirements:
◼ Implement a 2-D convolution using HLS C.
◼ Optimize the HLS with directives.
If by any means someone can be a help, I will be truly grateful. Kindly provide the source code if possible.
LikeLike